

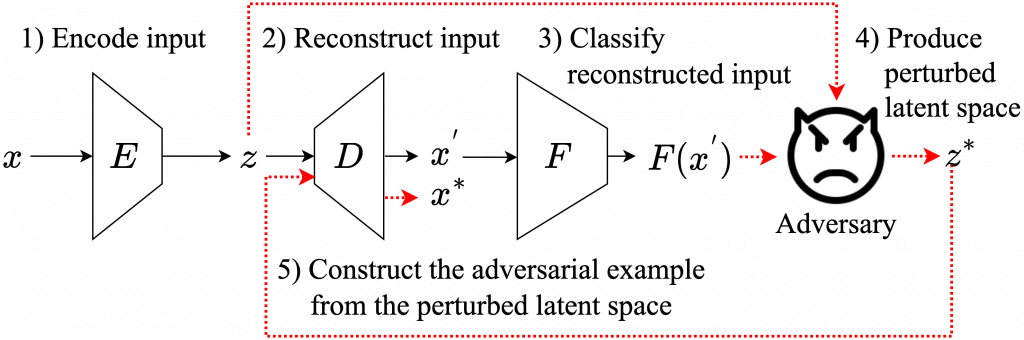
Recently, with the advancement of deep learning, several applications in text classification have advanced significantly. However, this improvement comes with a cost because deep learning is vulnerable to adversarial examples. This weakness indicates that deep learning is not very robust.
Fortunately, a couple of students in our lab, Korn Sooksatra and Bikram Khanal, noticed that the input of a text classifier is discrete. Hence, it can prevent the classifier from state-of-the-art attacks. Nonetheless, previous works have generated black-box attacks that successfully manipulate the discrete values of the input to find adversarial examples. Therefore, instead of changing the discrete values, they transform the input into its embedding vector containing real values to perform the state-of-the-art white-box attacks. Then, they convert the perturbed embedding vector back into a text and name it an adversarial example. In summary, PhD candidates, Sooksatra and Khanal, create a framework that measures the robustness of a text classifier by using the gradients of the classifier.
This paper was accepted for presentation and publication at the LXAI workshop at NeurIPS 2022 in New Orleans, LA. Download the paper here: [ bib | .pdf ]