The emergence of brain-computer interfaces (BCIs), particularly those developed by companies like Neuralink, represents a key convergence of neuroscience and AI. These technologies aim to facilitate direct communication between the human brain and external devices, offering wide-ranging applications in healthcare, education, and even entertainment. For instance, BCIs can assist people with disabilities or potentially boost cognitive functions in the general population. When AI is added to the mix, it can interpret neural signals in real-time, resulting in more natural and fluid ways of interacting with computers (İbişağaoğlu, 2024; Silva, 2018).
What Are BCIs?
A brain-computer interface is a system that establishes a direct communication pathway between the brain and an external device. The goal is to translate brain activity into actionable outputs, such as controlling a robotic arm or a computer cursor.
BCIs operate in two main modes:
- Open-loop systems: These send information from the brain to an external device but don’t provide feedback to the user. An example would be a system that controls a prosthetic hand based on neural signals without sensory feedback.
- Closed-loop systems: These provide feedback to the user, creating a dynamic interaction. For instance, a robotic limb that not only moves based on brain signals but also sends sensory feedback about grip strength (Voeneky et al., 2022).
Types of BCIs: Non-Invasive, Semi-Invasive, and Invasive
There are three primary types of BCIs, differentiated by how they access neural signals:
- Non-Invasive BCIs:
- These use external devices to read brain signals, typically via electroencephalography (EEG). EEG BCIs detect electrical activity from the scalp and are widely used in research and consumer applications like gaming and neurofeedback for mental health.Advantages: Low risk, no surgery required, relatively affordable.Limitations: Low signal resolution due to the skull dampening signals. This limits their use in high-precision tasks.
- Semi-Invasive BCIs:
- These involve placing electrodes on the surface of the brain but outside the brain tissue. This technique, known as electrocorticography (ECoG), is often used in medical settings.Advantages: Higher signal resolution compared to EEG, without penetrating brain tissue.Limitations: Requires surgery, so it’s less commonly used outside clinical or experimental settings.
- Invasive BCIs:
- These are the most advanced BCIs, involving implanted electrodes directly into brain tissue. The Utah Array, for instance, offers extremely high signal resolution by recording activity from individual neurons.Advantages: High precision, allowing for fine motor control and complex tasks like operating robotic limbs or even restoring movement in paralyzed individuals.Limitations: High risk of infection, expensive, and requires surgery.
Applications and Current Capabilities
BCI technology has practical applications in several fields:
- Assistive Technologies:
- BCIs allow people with disabilities to control wheelchairs, robotic arms, or communication devices. For example, people with ALS can use BCIs to type out words via thought alone (Salles, 2024).
- Rehabilitation:
- In closed-loop BCIs, neurofeedback can help stroke patients regain motor function by retraining brain circuits (Voeneky, 2022).
- Neuroscience Research:
- BCIs provide tools for understanding brain function, from motor control to decision-making processes (Kellmeyer, 2019).
- Consumer Applications:
- Emerging technologies are exploring non-invasive BCIs for gaming, meditation, and even controlling smart home devices (Silva, 2018).
The Future of BCIs
While BCIs hold great promise, several challenges prevent them from becoming affordable, practical tools for widespread use:
- Signal Quality and Noise:
- Non-invasive BCIs like EEG face significant signal interference from the skull and scalp, reducing their accuracy and reliability. Improving hardware to capture clearer signals without invasive procedures is a major hurdle (Sivanagaraju, 2024).
- Scalability and Cost:
- Invasive BCIs, such as those using the Utah Array, require complex surgical procedures and highly specialized equipment, driving up costs. Making these systems accessible at scale requires breakthroughs in manufacturing and less invasive implantation techniques (Yuste et al., 2017).
- Data Processing and AI:
- Decoding brain signals into usable outputs requires advanced algorithms and computational power. While machine learning has made strides, real-time, low-latency decoding remains a technical challenge, especially for complex tasks (İbişağaoğlu, 2024).
- Durability of Implants:
- For invasive systems, implanted electrodes face degradation over time due to the body’s immune response. Developing materials and designs that can endure for years without significant loss of function is essential for long-term use (Farisco et al., 2022).
- User Training and Usability:
- Current BCIs often require extensive training to operate effectively, which can be a barrier for users. Simplifying interfaces and reducing the learning curve are critical for consumer adoption (Silva, 2018).
These technical hurdles must be addressed to make BCIs a reliable, affordable, and practical reality. Overcoming these challenges will require innovations in materials, signal processing, and user interface design, all while ensuring safety and scalability.
Conclusion
BCIs are no longer science fiction. They are active tools in research, rehabilitation, and assistive technologies. The distinction between open-loop and closed-loop systems, as well as the differences between non-invasive, semi-invasive, and invasive approaches, defines the current landscape of BCI development. I hope this overview provides a solid foundation for exploring the ethical and philosophical questions that follow.
References:
- İbişağaoğlu, D. (2024). Neuro-responsive AI: Pioneering brain-computer interfaces for enhanced human-computer interaction. NFLSAI, 8(1), 115.
- Silva, G. (2018). A new frontier: the convergence of nanotechnology, brain-machine interfaces, and artificial intelligence. Frontiers in Neuroscience, 12.
- Voeneky, S., et al. (2022). Towards a governance framework for brain data. Neuroethics, 15(2).
- Kellmeyer, P. (2019). Artificial intelligence in basic and clinical neuroscience: opportunities and ethical challenges. Neuroforum, 25(4), 241-250.
- Yuste, R., et al. (2017). Four ethical priorities for neurotechnologies and AI. Nature, 551(7679), 159-163.
- Farisco, M., et al. (2022). On the contribution of neuroethics to the ethics and regulation of artificial intelligence. Neuroethics, 15(1).
- Salles, A. (2024). Neuroethics and AI ethics: A proposal for collaboration. BMC Neuroscience, 25(1).
- Sivanagaraju, D. (2024). Revolutionizing brain analysis: AI-powered insights for neuroscience. International Journal of Scientific Research in Engineering and Management, 08(12), 1-7.














 , and an alternative hypothesis,
, and an alternative hypothesis,  , based on the problem (comparing models). Both hypotheses must be concise, mutually exclusive, and exhaustive. For example, we could say that our null hypothesis is that the models perform equally, and the alternative could mean that the models perform differently.
, based on the problem (comparing models). Both hypotheses must be concise, mutually exclusive, and exhaustive. For example, we could say that our null hypothesis is that the models perform equally, and the alternative could mean that the models perform differently.
 value of the ANOVA test is less than the significance level (usually 0.05), we reject the null hypothesis and conclude that at least one of the means is different, i.e., at least one model performs differently than the others. However, ANOVA may not always be the best choice for comparing the performance of different models.
value of the ANOVA test is less than the significance level (usually 0.05), we reject the null hypothesis and conclude that at least one of the means is different, i.e., at least one model performs differently than the others. However, ANOVA may not always be the best choice for comparing the performance of different models.
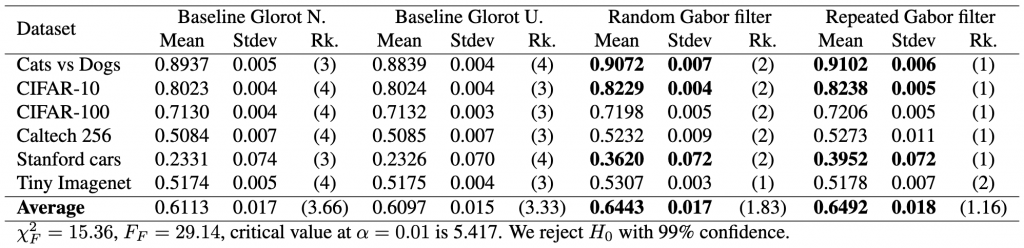
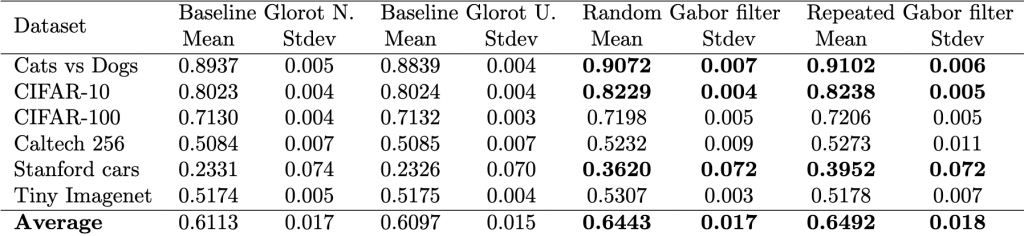
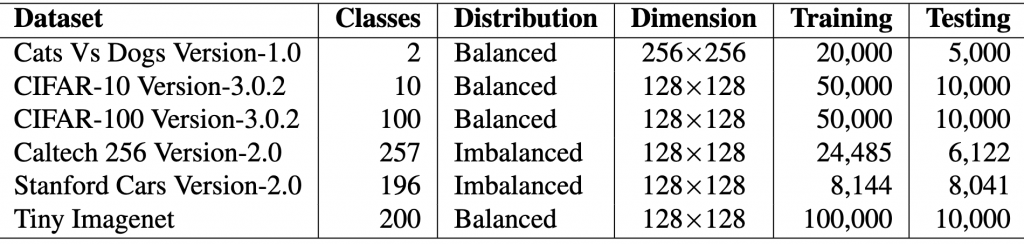
 different models, i.e., two baseline models, Gabor randomized, and Gabor repeated, on
different models, i.e., two baseline models, Gabor randomized, and Gabor repeated, on  datasets. First, the test calculates the average rank of each model’s performance on each dataset, with the best-performing model receiving a rank of 1. The Friedman test then tests the null hypothesis,
datasets. First, the test calculates the average rank of each model’s performance on each dataset, with the best-performing model receiving a rank of 1. The Friedman test then tests the null hypothesis, ![\begin{equation*} \chi_{F}^{2}=\frac{12 N}{k(k+1)}\left[\sum_{j=1}^{k} R_{j}^{2}-\frac{k(k+1)^{2}}{4}\right] \end{equation*}](https://baylor.ai/wp-content/ql-cache/quicklatex.com-e2518869970055a72a2524df63957827_l3.png "Rendered by QuickLaTeX.com")
 is the average ranking of each model.
is the average ranking of each model.
 is not less than the critical value for the
is not less than the critical value for the  distribution for a particular confidence value
distribution for a particular confidence value  . However, since
. However, since  statistic as follows:
statistic as follows:

 , and
, and 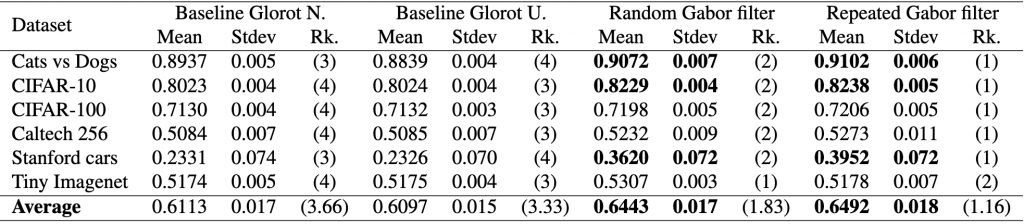
![\begin{align*} \chi_{F}^{2}&=\frac{12 \cdot 6}{4 \cdot 5}\left[\left(3.66^2+3.33^2+1.83^2+1.16^2\right)-\frac{4 \cdot 5^2}{4}\right] \nonumber \\ &=15.364 \nonumber \end{align*}](https://baylor.ai/wp-content/ql-cache/quicklatex.com-b7fd261f286621cdf8d57b028898841d_l3.png "Rendered by QuickLaTeX.com")

 is 5.417. Thus, because the critical value is below our statistics obtained, we reject
is 5.417. Thus, because the critical value is below our statistics obtained, we reject  ) is
) is  , that is the number of models minus one; the degrees of freedom across rows (denoted as
, that is the number of models minus one; the degrees of freedom across rows (denoted as  ) is
) is  , that is, the number of models minus one, times the number of datasets minus one. In our case this is
, that is, the number of models minus one, times the number of datasets minus one. In our case this is  and
and  .
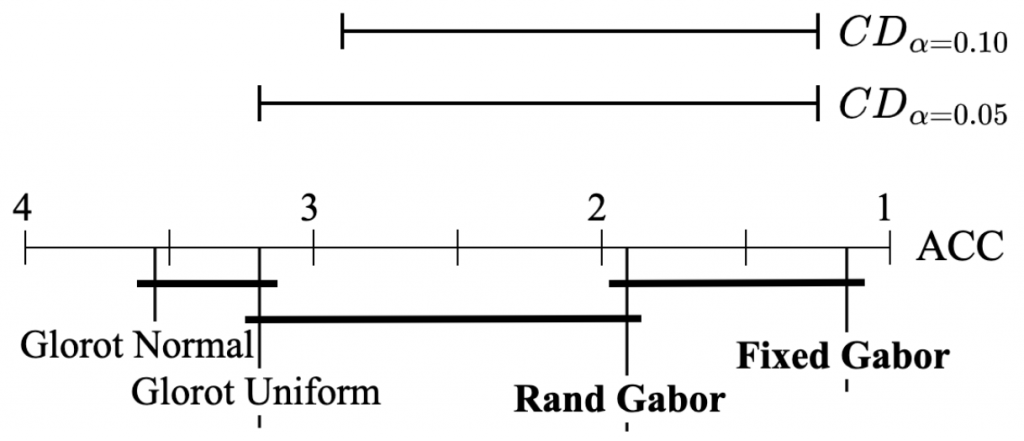
.![\[CD = q_{\alpha} \sqrt{\frac{k(k+1)}{6N}}\]](https://baylor.ai/wp-content/ql-cache/quicklatex.com-31ddfa7633974f9a4c569740f85c93b8_l3.png "Rendered by QuickLaTeX.com")
 is the critical difference of the Studentized range distribution at the chosen significance level and
is the critical difference of the Studentized range distribution at the chosen significance level and  is the number of groups. The
is the number of groups. The 


 , we conclude Gabor is better. Similarly, since the difference in rank between the fixed Gabor and baseline Glorot uniform is 2.17 and is less than the
, we conclude Gabor is better. Similarly, since the difference in rank between the fixed Gabor and baseline Glorot uniform is 2.17 and is less than the  , we conclude that Gabor is better. Yes, there is sufficient statistical evidence to show that our model is better with high confidence.
, we conclude that Gabor is better. Yes, there is sufficient statistical evidence to show that our model is better with high confidence.