
As a quantum machine learning (QML) researcher, I’m constantly fascinated by quantum computers’ potential to revolutionize the way we learn from data. We’re living in a time when quantum computers are starting to become a reality, and their potential to revolutionize machine learning is simply mind-blowing. But there’s a catch, and it’s a big one: noise.
Right now, we’re in the era of Noisy Intermediate-Scale Quantum (NISQ) devices. These early quantum computers are incredibly powerful, but they’re also extremely sensitive to errors. And when it comes to machine learning, these errors can be a real deal-breaker. That’s because a core principle of machine learning is generalization: the ability of a model to perform well on unseen data. If our quantum machine learning models are constantly being tripped up by noise, how can we trust them to make accurate predictions in the real world?
That’s where generalization bounds come into play. These are mathematical guarantees that tell us how well a model is expected to perform on unseen data. In the classical realm, generalization bounds are well-established and have proven invaluable in guiding model development and deployment. However, in the quantum domain, particularly in the context of NISQ devices, these bounds are still being actively explored and refined.
We recently published a systematic mapping study article, “Generalization error bound for quantum machine learning in NISQ era—a survey,” that specifically focuses on the generalization bounds for supervised QML in the NISQ era. Our work meticulously analyzed 37 (out of 544) relevant research articles to understand the current state-of-the-art and identify trends and challenges in this critical area. Their work provides valuable insights that can guide future research and development in QML.
Let’s take a look at some of the key findings of this study.
Quantum Noisy Channel Limits Current Quantum Machine Learning Capabilities
The idea behind QML is to leverage the unique properties of quantum systems, like superposition and entanglement, to develop algorithms that can outperform classical machine learning approaches for certain tasks. And our findings do suggest that this quantum advantage is within reach. For instance, some of the generalization bounds proposed in the considered literature suggest that QML models can achieve better performance with smaller datasets compared to classical models, especially when dealing with high-dimensional data. This is huge! Imagine being able to train powerful machine learning models with a fraction of the data we need today. But there’s a flip side. These same bounds also highlight the delicate interplay between noise, model complexity, and generalization. Deeper quantum circuits, while potentially more expressive, are particularly vulnerable to noise accumulation, leading to degradation in performance. This means that while we might be able to achieve a quantum advantage, we need to be very careful about how we design our QML models. We need to strike a balance between expressiveness and noise resilience, which is no easy feat.
Measurement Does Introduce Error
Here’s another wrinkle: measurement. It turns out that simply extracting information from a quantum system can introduce errors, and these errors can affect the generalization ability of our QML models. This means we can’t just focus on building fancy quantum algorithms; we also need to develop robust measurement strategies that minimize information loss. And this becomes even more critical in the presence of noise.
Dataset Choices in Quantum Machine Learning Reflect a Familiarity Bias
The study highlights an interesting trend in dataset selection for QML research. On the one hand, we see a lot of work using synthetic datasets specifically designed to showcase the potential of QML. This makes sense; we need to understand how these models work in ideal settings before we can tackle real-world problems. On the other hand, there’s also a tendency to use familiar classical datasets like MNIST and IRIS, which are benchmarks in the classical machine-learning world. Now, there’s nothing inherently wrong with using classical datasets, but it does raise a few concerns. First, it creates a temptation to directly compare the performance of QML models with their classical counterparts, which might not be the most meaningful comparison. Remember, we’re not just trying to build quantum versions of classical algorithms; we’re trying to tap into something fundamentally different. Second, these classical datasets might not be the best for highlighting the specific advantages of quantum algorithms. They might not even be solvable more efficiently on a quantum computer! This reliance on familiar datasets, while useful for benchmarking and comparison, can inadvertently lead to what I call “familiarity bias.”
We risk falling into the trap of constantly comparing quantum models to classical counterparts, potentially obscuring the specific advantages quantum algorithms might offer. The question then becomes: Are we prioritizing familiarity over the pursuit of quantum advantage?
The Frequent Use of IBM’s Quantum Platforms May Lead to Research Bias
Another interesting tidbit from our findings is the apparent popularity of the IBM Quantum Platform among researchers. While this platform is certainly a frontrunner in the quantum computing race, this preference could lead to research biases. Different quantum computing platforms have different noise characteristics, gate fidelities, and qubit connectivity, all of which can affect algorithm performance. So, if we’re primarily focusing on one platform, we might be missing out on valuable insights that other platforms could offer.
Classical Optimization Techniques is an Intermediate Stop
Another interesting observation is the widespread use of classical optimization techniques like stochastic gradient descent (SGD) and backpropagation in QML. While these techniques have proven incredibly successful in classical machine learning, their suitability for optimizing quantum circuits, particularly in the presence of noise, is still a topic of active debate. While there have been quite a few works on the ‘Parameter-shift’, ‘finite differential’, and ‘Hadamard test’ gradient approach our study emphasizes that the highly non-convex optimization landscape of quantum models can significantly limit the effectiveness of classical techniques.
This raises the question: Are we limiting the potential of QML by relying on classical optimization techniques? Perhaps exploring and developing quantum-specific optimization algorithms could lead to more efficient and effective training procedures.
Quantum Kernels Offer Advantages But Require Further Exploration
A significant portion of the analyzed research focuses on quantum kernel methods. These methods aim to leverage the mathematical power of kernel theory within a quantum framework, potentially leading to improved generalization capabilities for QML models. The study also points out that quantum kernel methods can often achieve competitive performance with simpler circuit architectures compared to other QML approaches, which is particularly advantageous in the noise-prone NISQ era.
However, as promising as they are, quantum kernels aren’t without their challenges. Research suggests that under certain conditions, the values of quantum kernels can exhibit exponential concentration, leading to poor generalization performance. This phenomenon highlights the need for a deeper understanding of the interplay between kernel design, data embedding, and noise mitigation strategies.
Quantum Machine Learning Research Is Exploring a Variety of Approaches
We found the diversity in research approaches, with a mix of theoretical and empirical work, and a particular focus on kernel methods and ensemble learning. While this diversity is valuable, it also risks fragmenting the field. We need a more unified approach, one that combines the rigor of theoretical analysis with the practicality of experimental validation. While theoretical bounds provide valuable insights into the expected behavior of quantum models, their practical relevance hinges on their validation under realistic, noisy conditions. This calls for a more collaborative and iterative approach to research, where theoretical insights guide experimental design, and experimental findings inform further theoretical development.
The Field of Quantum Machine Learning Needs a Unified Approach
The findings of this study reinforce the idea that QML is a nascent field, full of potential but facing unique challenges in the NISQ era. To effectively navigate these challenges, we, as a community, need to adopt a more unified and collaborative approach. This involves:
- Sharing knowledge: Openly sharing insights about generalization bounds, measurement complexities, dataset choices, and optimization techniques will accelerate the overall progress of the field.
- Embracing diversity: While standardization can be beneficial, we shouldn’t limit ourselves to a single platform, such as IBM hardware, or a narrow set of techniques. Exploring diverse platforms and approaches will lead to a more robust and adaptable field.
- Prioritizing quantum-specific solutions: While borrowing from classical techniques can be helpful, we must actively invest in developing quantum-specific algorithms and optimization strategies to fully unlock the power of quantum computing in machine learning.
Future Quantum Machine Learning Research Must Address Several Challenges
Navigating the noisy quantum landscape is not going to be easy. But the potential rewards are simply too great to ignore. As we move forward, we need to focus on:
- Developing generalization bounds and other metrics that accurately reflect the challenges of the NISQ era.
- Designing robust QML algorithms that can tolerate noise and efficiently extract information from quantum systems.
- Exploring a diverse range of datasets that can showcase the unique advantages of quantum algorithms.
- Embracing a multi-platform approach to ensure the reproducibility and generalizability of research findings.
The quest for a quantum advantage in machine learning is just beginning. And while there are many hurdles to overcome, the journey itself is a testament to human ingenuity. I, for one, am excited to see what the future holds for this revolutionary field.
For a detailed exploration of the methodology and findings, read the full paper here.
References
- Khanal, B., Rivas, P., Sanjel, A. et al. Generalization error bound for quantum machine learning in NISQ era—a survey. Quantum Mach. Intell. 6, 90 (2024). https://doi.org/10.1007/s42484-024-00204-w
About the Author
Bikram Khanal is a Ph.D. student at Baylor University, specializing in Quantum Machine Learning and Natural Language Processing.
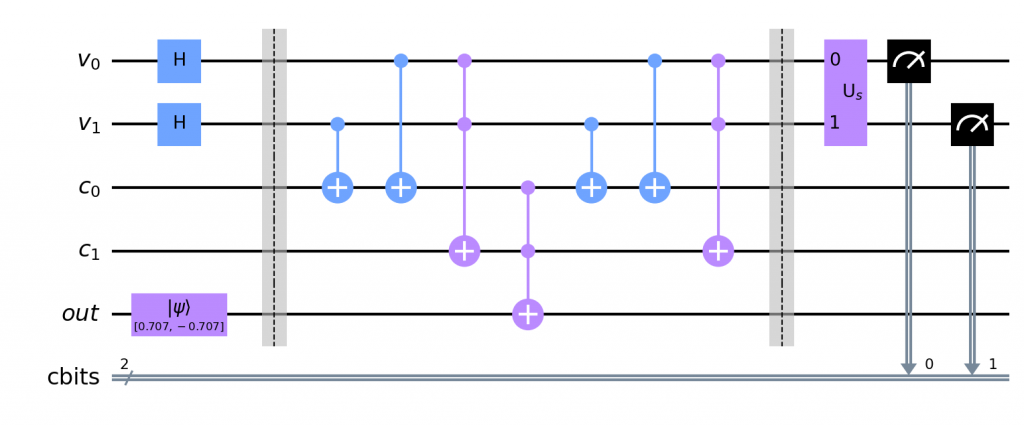
![\[\min_{\mathcal{O}}\mathbb{E}[ \left | \langle{\psi}| \mathcal{O} |{\psi} \rangle - \langle{\psi} | \mathcal{O}_n |{\psi} \rangle ]\]](https://baylor.ai/wp-content/ql-cache/quicklatex.com-3cfa5f0083acaa8744a5fc03feba12bf_l3.png "Rendered by QuickLaTeX.com")
 is a Pauli-Z observable, and
is a Pauli-Z observable, and  is an observable we are trying to learn. The expectation value is computed before and after noise is introduced. The goal is to find an observable that minimizes this difference, effectively learning a robust observable.
is an observable we are trying to learn. The expectation value is computed before and after noise is introduced. The goal is to find an observable that minimizes this difference, effectively learning a robust observable.
 . The expectation values of the observable
. The expectation values of the observable  on the depolarized Bell state as a function of the depolarization rate
on the depolarized Bell state as a function of the depolarization rate  are plotted in the following figure.
are plotted in the following figure.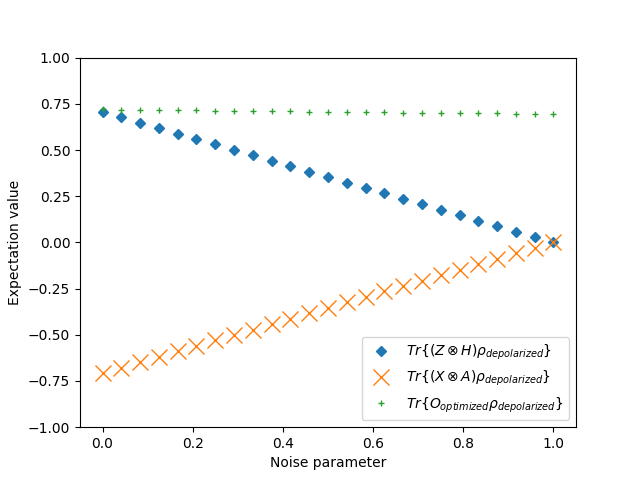
 is the Pauli-Z matrix,
is the Pauli-Z matrix,  is the Pauli-X matrix,
is the Pauli-X matrix,  is the Hadamard gate,
is the Hadamard gate,  is an arbitrary observable, and
is an arbitrary observable, and  . In the traditional depolarization model, noise can be introduced by applying the three Pauli matrices — X, Y, and Z to
. In the traditional depolarization model, noise can be introduced by applying the three Pauli matrices — X, Y, and Z to 

![\[\begin{array}{cc}K_0 = \sqrt{1 -\frac{2p}{3}} \mathbb{I}, &K_1 = i \sqrt{\frac{2p}{3}} ZX .\end{array}\]](https://baylor.ai/wp-content/ql-cache/quicklatex.com-761f1150ca77b3315da52d621ec221e0_l3.png "Rendered by QuickLaTeX.com")
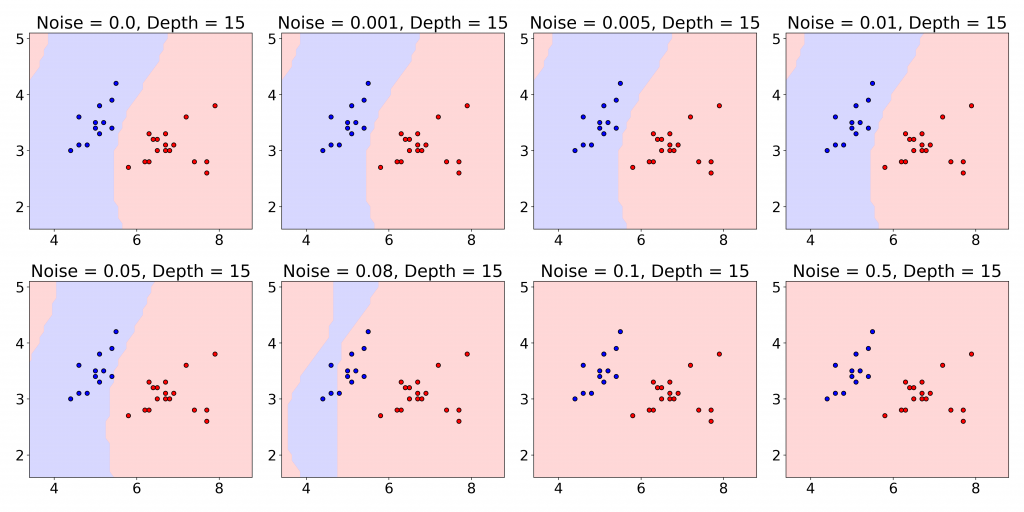

 training examples
training examples  would give rise to a prediction model
would give rise to a prediction model  with
with

 . Hence, with
. Hence, with  training data, one can train a classical ML model to predict the function
training data, one can train a classical ML model to predict the function  up to an additive prediction error
up to an additive prediction error  .” They also show that a slight geometric difference between kernel functions defined by classical and quantum ML guarantees similar or better performance in prediction by classical ML. On the other hand, a sizeable geometric difference indicates the possibility of a large prediction advantage using the quantum ML model.
.” They also show that a slight geometric difference between kernel functions defined by classical and quantum ML guarantees similar or better performance in prediction by classical ML. On the other hand, a sizeable geometric difference indicates the possibility of a large prediction advantage using the quantum ML model.