K. Sooksatra, G. Bejarano, and P. Rivas, “Evaluating Robustness of Reconstruction Models with Adversarial Networks,” Procedia Computer Science, vol. 222, pp. 353-366, 2023. https://doi.org/10.1016/j.procs.2023.08.174.
In the ever-evolving landscape of artificial intelligence, our lab has made a significant breakthrough with our latest publication featured in Procedia Computer Science. This research, spearheaded by Korn Sooksatra, delves into the critical domain of adversarial robustness, mainly focusing on reconstruction models, which, until now, have been a less explored facet of adversarial research. This paper was accepted initially into IJCNN and chosen to be added to the INNS workshop and published as a journal article.
Key Takeaways:
- Innovative Frameworks: The team introduced two novel frameworks for assessing adversarial robustness: the standard framework, which perturbs input images to deceive reconstruction models, and the universal-attack framework, which generates adversarial perturbations from a dataset’s distribution.
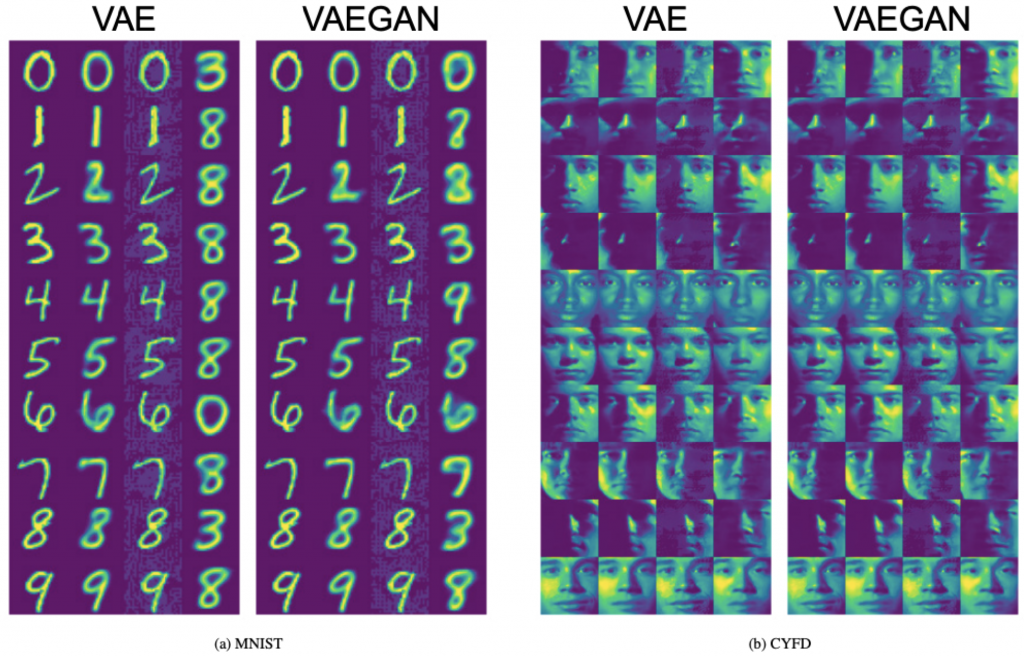
- Outperforming Benchmarks: Through rigorous testing on MNIST and Cropped Yale Face datasets, these frameworks demonstrated superior performance in altering image reconstruction and classification, surpassing existing state-of-the-art adversarial attacks.
- Enhancing Model Resilience: A pivotal aspect of the study was using these frameworks to retrain reconstruction models, significantly improving their defense against adversarial perturbations and showcasing an ethical application of adversarial networks.
- Latent Space Analysis: The research also included a thorough examination of the latent space, ensuring that adversarial attacks do not compromise the underlying features that are crucial for reconstruction integrity.
Broader Impact:
The implications of this research are profound for the AI community. It not only presents a method to evaluate and enhance the robustness of reconstruction models but also opens avenues for applying these frameworks to other image-to-image applications. The lab’s work is a call to the AI research community to prioritize the development of robust AI systems that can withstand adversarial threats, ensuring the security and reliability of AI applications across various domains.
Future Directions:
While the frameworks developed are groundbreaking, the team acknowledges the need for reduced preprocessing time to enhance practicality. Future work aims to refine these frameworks and extend their application to other domains, such as video keypoint interpretation, anomaly detection, and graph prediction.