In today’s digital age, trust has become a precious commodity. It’s the invisible currency that fuels our interactions with technology and brands. Building trust, especially in technology, is a costly and time-consuming process. However, the payoff is immense. When users trust a system or a brand, they are more likely to engage with it, advocate for it, and remain loyal even when faced with alternatives.
One of the most effective ways to build trust in technology is to ensure it aligns with societal goals and values. When a system or technology operates in a way that benefits society and adheres to its values, it is more likely to be trusted and accepted.
However, artificial intelligence (AI) has faced significant challenges. Despite its immense potential and numerous benefits, trust in AI has suffered. This is due to various factors, including concerns about privacy, transparency, potential biases, and the lack of a clear ethical framework guiding its use.
This is where the concept of AI Orthopraxy comes in. AI Orthopraxy is all about the correct practice of AI. It’s about ensuring that AI is developed and used in a way that is ethical, responsible, and aligned with societal values. It’s about walking the talk of trustworthy AI.
In this talk, I will discuss the concept of AI Orthopraxy, the recent developments in AI, the associated risks, and the tools and strategies we can use to ensure the responsible use of AI. The goal is not just to highlight the challenges but also to provide a roadmap for moving forward in a way that is beneficial for all stakeholders.
Large Language Models (LLMs) and Large Multimodal Models: The Ethical Implications
The journey of Large Language Models (LLMs) has been remarkable. From the early successes of models like GPT and BERT, we have seen a rapid evolution in the capabilities of these models. The most recent iterations, such as ChatGPT, have demonstrated an impressive ability to generate human-like text, opening up many applications in areas like customer service, content creation, and more.
Parallel to this, the field of vision models has also seen significant advancements. Introducing models like Vision Transformer (ViT) has revolutionized how we process and understand visual data, leading to breakthroughs in medical imaging, autonomous driving, and more.
However, as with any powerful technology, these models come with their own challenges. One of the most concerning is their fragility, especially when faced with adversarial attacks. These attacks, which involve subtly modifying input data to mislead the model, have exposed the vulnerabilities of these models and raised questions about their reliability.
As someone deeply involved in this space, I see both the immense potential of these models and the serious risks they pose. But I firmly believe these risks can be mitigated with careful engineering and regulation.
Careful engineering involves developing robust models resistant to adversarial attacks and biases. It involves ensuring transparency in how these models work and making them interpretable so that their decisions can be understood and scrutinized.
On the other hand, regulation involves setting up rules and standards that guide the development and use of these models. It involves ensuring that these models are used responsibly and ethically and that there are mechanisms in place to hold those who misuse them accountable.
AI Ethics Standards: The Need for a Common Framework
Standards play a crucial role in ensuring technology’s responsible and ethical use. In the context of AI, they can help make systems fair, accountable, and transparent. They provide a common framework that guides the development and use of AI, ensuring that it aligns with societal values and goals.
One of the key initiatives in this space is the P70XX series of standards developed by the IEEE. These standards address various ethical considerations in system and software engineering and provide guidelines for embedding ethics into the design process.
Similarly, the International Organization for Standardization (ISO) has been working on standards related to AI. These standards cover various aspects of AI, including its terminology, trustworthiness, and use in specific sectors like healthcare and transportation.
The National Institute of Standards and Technology (NIST) has led efforts to develop a framework for AI standards in the United States. This framework aims to support the development and use of trustworthy AI systems and to promote innovation and public confidence in these systems.
The potential of these standards goes beyond just guiding the development and use of AI. There is a growing discussion about the possibility of these standards becoming recommended legal practice. This would mean that adherence to these standards would not just be a matter of ethical responsibility but also a legal requirement.
This possibility underscores the importance of these standards and their role in ensuring the responsible and ethical use of AI. However, standards alone are not enough. They need to be complemented by best practices in AI.
AI Best Practices: From Theory to Practice
As we navigate the complex landscape of AI ethics, best practices serve as our compass. They provide practical guidance on how to implement the principles of ethical AI in real-world systems.
One such best practice is the use of model cards for AI models. Model cards are like nutrition labels for AI models. They provide essential information about a model, including its purpose, performance, and potential biases. By providing this information, model cards help users understand what a model does, how well it does, and any limitations it might have.
Similarly, data sheets for datasets provide essential information about the datasets used to train AI models. They include details about the data collection process, the characteristics of the data, and any potential biases in the data. This helps users understand the strengths and weaknesses of the dataset and the models trained on it.
A newer practice is the use of Data Statements for Natural Language Processing, proposed to mitigate system bias and enable better science in NLP technologies. Data Statements are intended to address scientific and ethical issues arising from using data from specific populations in developing technology for other populations. They are designed to help alleviate exclusion and bias in language technology, lead to better precision in claims about how NLP research can generalize, and ultimately lead to language technology that respects its users’ preferred linguistic style and does not misrepresent them to others.
However, these best practices are only effective if a trained workforce understands them and can implement them in their work. This underscores the importance of education and training in AI ethics. It’s not enough to develop ethical AI systems; we must cultivate a workforce that can uphold these ethical standards in their work. Initiatives like the CSEAI promote responsible AI and develop a workforce equipped to navigate AI’s ethical challenges.
The Role of the CSEAI in Promoting Responsible AI
The Center for Standards and Ethics in AI (CSEAI) is pivotal in promoting responsible AI. Our mission at CSEAI is to provide applicable, actionable standard practices in trustworthy AI. We believe the path to responsible AI lies in the intersection of robust technical standards and ethical solid guidelines.

One of the critical areas of our work is developing these standards. We work closely with researchers, practitioners, and policymakers to develop standards that are technically sound and ethically grounded. These standards provide a common framework that guides the development and use of AI, ensuring that it aligns with societal values and goals.
In addition to developing standards, we also focus on state-of-the-art collaborative AI research and workforce development. We believe that responsible AI requires a workforce that is not just technically competent but also ethically aware. To this end, we offer training programs and resources that help individuals understand the ethical implications of AI, upcoming regulations, and the importance of bare minimum practices like Model Cards, Datasheets for Datasets, and Data Statements.
As the field of AI continues to evolve, so does the landscape of regulation, standardization, and best practices. At CSEAI, we are committed to staying ahead of these changes. We continuously update our value propositions and training programs to reflect the latest developments in the field and to ensure our standards and practices align with emerging regulations.
As the CSEAI initiative moves forward, we aim to ensure that AI is developed and used in a way that is beneficial for all stakeholders. We believe that with the right standards and practices, we can harness the power of AI in a way that is responsible, ethical, and aligned with societal values in a manner that is profitable for our industry partners and safe, robust, and trustworthy for all users.
Conclusion: The Future of Trustworthy AI
As we look toward the future of AI, we find ourselves amidst a cacophony of voices. As my colleagues put it, on one hand, we have the “AI Safety” group, which often stokes fear by highlighting existential risks from AI, potentially distracting from immediate concerns while simultaneously pushing for rapid AI development. On the other hand, we have the “AI Ethics” group, which tends to focus on the faults and dangers of AI at every turn, creating a brand of criticism hype and advocating for extreme caution in AI use.
However, most of us in the AI community operate in the quiet middle ground. We recognize the immense benefits that AI can bring to sectors like healthcare, education, and vision, among others. At the same time, we are acutely aware of the severe risks and harms that AI can pose. But we firmly believe that, like with electricity, cars, planes, and other transformative technologies, these risks can be minimized with careful engineering and regulation.

Consider the analogy of seatbelts in cars. Initially, many people resisted their use. We felt safe enough, with our mothers instinctively extending an arm in front of us during sudden stops. But when a serious accident occurred, the importance of seatbelts became painfully clear. AI regulation can be seen in a similar light. There may be resistance initially, but with proper safeguards in place, we can ensure that when something goes wrong—and it inevitably will—we will all be better prepared to handle it. More importantly, these safeguards will be able to protect those who are most vulnerable and unable to protect themselves.

As we continue to navigate the complex landscape of AI, let’s remember to stay grounded, to focus on the tangible and immediate impacts of our work, and to always strive for the responsible and ethical use of AI. Thank you.

This is a ChatGPT-generated summary of a noisy transcript of a keynote presented at Marist College on Tuesday, June 13, 2023, at 9 am as part of the Enterprise Computing Conference in Poughkeepsie, New York.








 , and an alternative hypothesis,
, and an alternative hypothesis,  , based on the problem (comparing models). Both hypotheses must be concise, mutually exclusive, and exhaustive. For example, we could say that our null hypothesis is that the models perform equally, and the alternative could mean that the models perform differently.
, based on the problem (comparing models). Both hypotheses must be concise, mutually exclusive, and exhaustive. For example, we could say that our null hypothesis is that the models perform equally, and the alternative could mean that the models perform differently.
 value of the ANOVA test is less than the significance level (usually 0.05), we reject the null hypothesis and conclude that at least one of the means is different, i.e., at least one model performs differently than the others. However, ANOVA may not always be the best choice for comparing the performance of different models.
value of the ANOVA test is less than the significance level (usually 0.05), we reject the null hypothesis and conclude that at least one of the means is different, i.e., at least one model performs differently than the others. However, ANOVA may not always be the best choice for comparing the performance of different models.
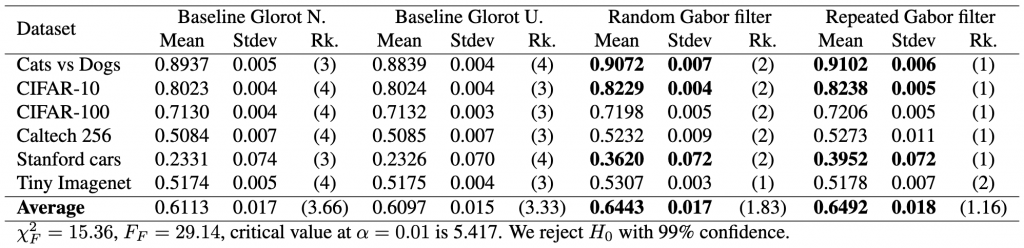
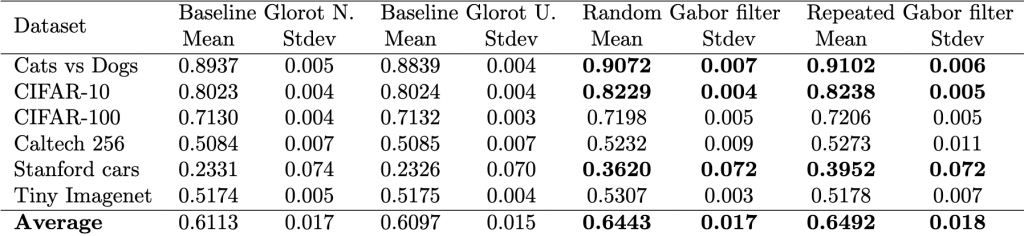
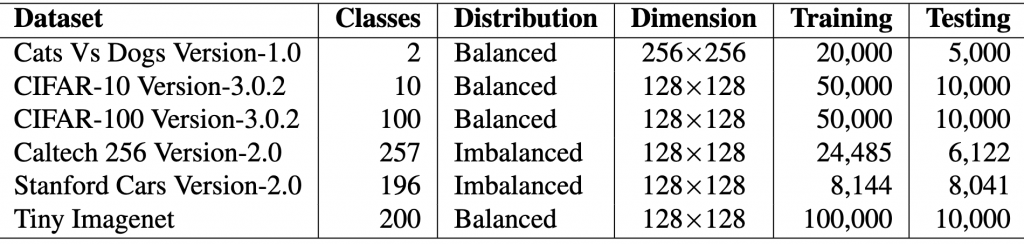
 different models, i.e., two baseline models, Gabor randomized, and Gabor repeated, on
different models, i.e., two baseline models, Gabor randomized, and Gabor repeated, on  datasets. First, the test calculates the average rank of each model’s performance on each dataset, with the best-performing model receiving a rank of 1. The Friedman test then tests the null hypothesis,
datasets. First, the test calculates the average rank of each model’s performance on each dataset, with the best-performing model receiving a rank of 1. The Friedman test then tests the null hypothesis, ![\begin{equation*} \chi_{F}^{2}=\frac{12 N}{k(k+1)}\left[\sum_{j=1}^{k} R_{j}^{2}-\frac{k(k+1)^{2}}{4}\right] \end{equation*}](https://baylor.ai/wp-content/ql-cache/quicklatex.com-e2518869970055a72a2524df63957827_l3.png "Rendered by QuickLaTeX.com")
 is the average ranking of each model.
is the average ranking of each model.
 is not less than the critical value for the
is not less than the critical value for the  distribution for a particular confidence value
distribution for a particular confidence value  . However, since
. However, since  statistic as follows:
statistic as follows:

 , and
, and 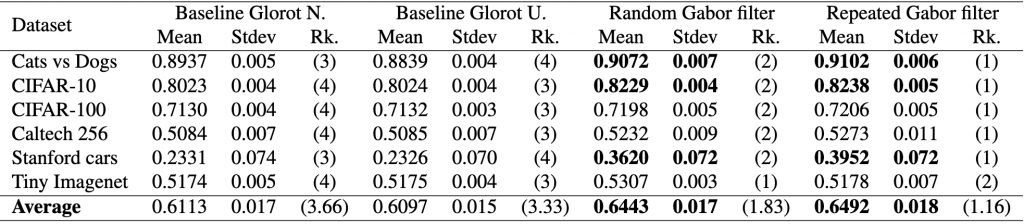
![\begin{align*} \chi_{F}^{2}&=\frac{12 \cdot 6}{4 \cdot 5}\left[\left(3.66^2+3.33^2+1.83^2+1.16^2\right)-\frac{4 \cdot 5^2}{4}\right] \nonumber \\ &=15.364 \nonumber \end{align*}](https://baylor.ai/wp-content/ql-cache/quicklatex.com-b7fd261f286621cdf8d57b028898841d_l3.png "Rendered by QuickLaTeX.com")

 is 5.417. Thus, because the critical value is below our statistics obtained, we reject
is 5.417. Thus, because the critical value is below our statistics obtained, we reject  ) is
) is  , that is the number of models minus one; the degrees of freedom across rows (denoted as
, that is the number of models minus one; the degrees of freedom across rows (denoted as  ) is
) is  , that is, the number of models minus one, times the number of datasets minus one. In our case this is
, that is, the number of models minus one, times the number of datasets minus one. In our case this is  and
and  .
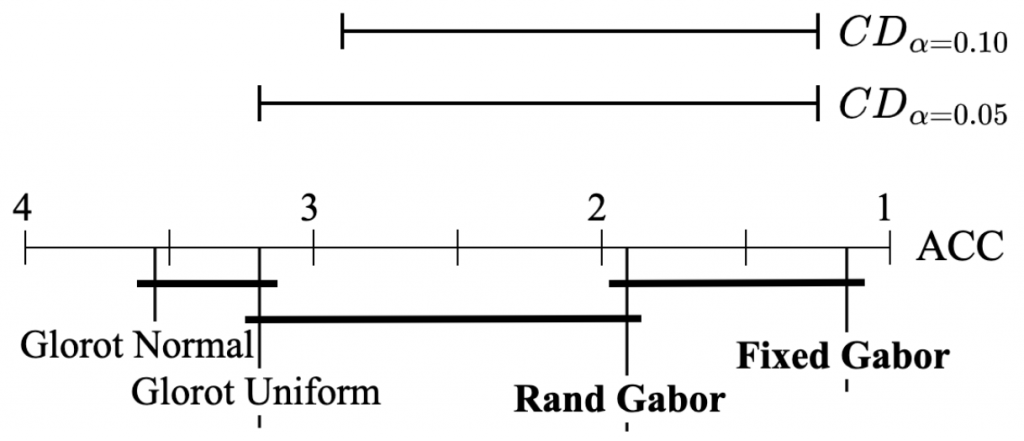
.![\[CD = q_{\alpha} \sqrt{\frac{k(k+1)}{6N}}\]](https://baylor.ai/wp-content/ql-cache/quicklatex.com-31ddfa7633974f9a4c569740f85c93b8_l3.png "Rendered by QuickLaTeX.com")
 is the critical difference of the Studentized range distribution at the chosen significance level and
is the critical difference of the Studentized range distribution at the chosen significance level and  is the number of groups. The
is the number of groups. The 


 , we conclude Gabor is better. Similarly, since the difference in rank between the fixed Gabor and baseline Glorot uniform is 2.17 and is less than the
, we conclude Gabor is better. Similarly, since the difference in rank between the fixed Gabor and baseline Glorot uniform is 2.17 and is less than the  , we conclude that Gabor is better. Yes, there is sufficient statistical evidence to show that our model is better with high confidence.
, we conclude that Gabor is better. Yes, there is sufficient statistical evidence to show that our model is better with high confidence.