Rivas, P.; Zhao, L. Marketing with ChatGPT: Navigating the Ethical Terrain of GPT-Based Chatbot Technology. AI2023, 4, 375-384. https://doi.org/10.3390/ai4020019
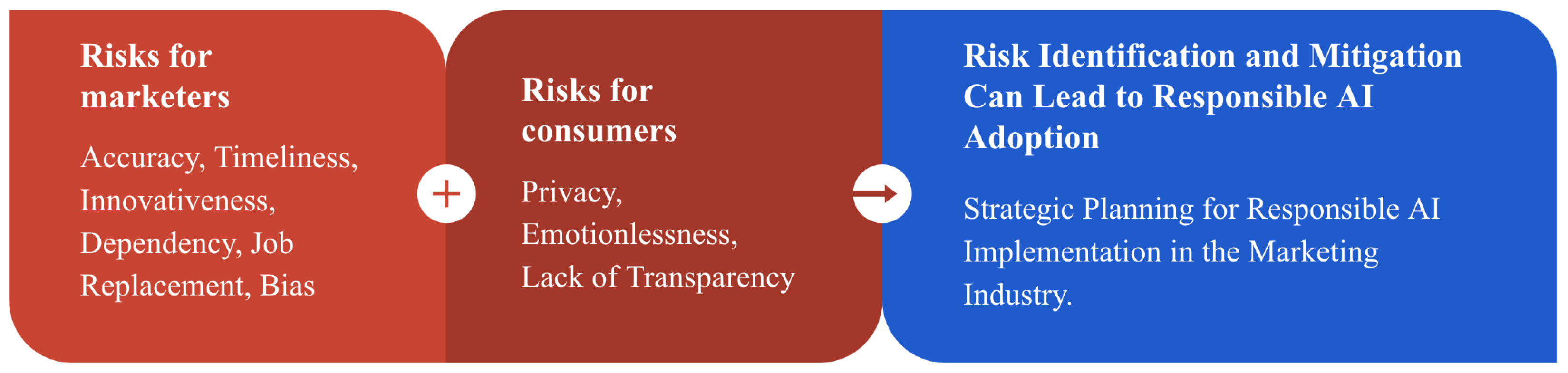
In the dynamic marketing world, the advent of AI-powered chatbot platforms like ChatGPT is a game-changer. This technology, leveraging natural language processing and machine learning, transforms how we interact with AI, offering significant advantages over previous tools. The open-access paper delves into the potential of ChatGPT to revolutionize marketing, provided ethical considerations are taken into account.
The paper argues that ChatGPT can accelerate content creation, enhance market research efficiency, and improve customer service automation. However, it also brings to light the ethical implications and potential risks for marketers, consumers, and other stakeholders. The ethical use of ChatGPT in marketing hinges on transparency, bias mitigation, privacy protection, and continuous monitoring to avoid potential harm while capitalizing on its benefits.
For marketing professionals, this paper is a crucial read to understand how to responsibly integrate ChatGPT into their strategies and ensure that its deployment enhances customer value without compromising ethical standards. Read the paper for free here.
I was honored to recently receive the ACM Senior Member designation from the Association for Computing Machinery (ACM). For my students who asked and anyone else interested, I would like to share with you what this honor is and why I received it.
First, let me tell you a little bit about the ACM. The ACM is the world’s largest educational and scientific computing society, with a mission to advance computing as a science and profession. The ACM Senior Member designation is a distinction awarded to members who have demonstrated significant accomplishments and impact in the computing field. To be considered for this honor, a candidate must have at least 10 years of professional experience in computing and have made significant contributions to the field through research, industry, or education. Being elevated to senior member status in ACM signifies that you are an established leader in the computing field, recognized by your peers for your expertise and contributions. It also comes with certain benefits, such as access to special resources and opportunities for professional development and networking.
Overall, being a senior member of ACM is a great honor and a recognition of your significant contributions to the computing field. 🫶
I was thrilled to learn that by recommendation of my mentor in the computer science department, Dr. Hamerly, the dean of the school of engineering and computer science, Dr. Baker, and of my peers, I am now an ACM Senior Member, and I believe that my contributions to the computing field over the past decade played a significant role in this recognition. Some of my most notable achievements include the following:
Technical leadership: leading industry-university collaborative projects, securing funding for students’ research, directing numerous theses and independent studies, developing graduate courses on data mining and machine learning, updating and developing courses, and participating in the education committees at Marist College and Baylor University.
Technical contributions: over 90 publications, research in machine learning and numerical optimization, contribution to SVM theory, recent research in efficient representation learning, adversarial learning, and ethical implications of biased and unfair models, and active involvement in developing AI ethics standards through work with IEEE Standards Association.
Professional contributions: participation in professional events, including serving as Sponsorship & Budget chair of ACM NYC of Women in Computing and as a Program Committee Chair for NAACL 2022 LXNLP workshop, active membership in professional organizations, and full-time industry experience designing end-to-end systems to support manufacturing and supply management.
Recognition: elevation to IEEE Senior Member, sought-after expertise and leadership in deep learning and ethics, involvement in developing AI ethics standards, and commitment to promoting diversity and inclusion in computing through work with ACM NYC of Women in Computing and participation in the AAAI Undergraduate Consortium.
My peers in the computing community have recognized these accomplishments and contributed to advancing the field. In addition to my technical contributions, I have been actively mentoring and teaching the next generation of computing professionals.
I am incredibly grateful to the ACM for this honor, and I hope it inspires some of my students to pursue academic excellence. I believe that we can all make a massive difference in the world through our work in computing, and I look forward to continuing to make meaningful contributions to the exciting and rapidly evolving field of machine learning and responsible AI.
Thank you for taking the time to read about my journey to becoming an ACM Senior Member. If you have any questions or would like to learn more about my work, please don’t hesitate to contact me.
Dr. Hamerly, chair of the computer science department and mentor, presented the ACM Senior Member certificate.
In the rapidly evolving world of artificial intelligence (AI), the IEEE Transactions on Technology and Society recently published a special issue that delves into the heart of AI’s most pressing challenges and opportunities. This editorial piece has garnered widespread attention. Read the full editorial here.
J. R. Schoenherr, R. Abbas, K. Michael, P. Rivas and T. D. Anderson, “Designing AI Using a Human-Centered Approach: Explainability and Accuracy Toward Trustworthiness,” in IEEE Transactions on Technology and Society, vol. 4, no. 1, pp. 9-23, March 2023, doi: 10.1109/TTS.2023.3257627.
The Essence of the Special Issue
This special issue comprises eight thought-provoking papers that collectively address the multifaceted nature of AI. The journey begins with a reconceptualization of AI, leading to discussions on the pivotal role of explainability and accuracy in AI systems. The papers emphasize that designing AI with a human-centered approach while recognizing the importance of ethics is not a zero-sum game.
Key Highlights
Reconceptualizing AI: Clarke, a Fellow of the Australian Computer Society, revisits the original conception of AI and proposes a fresh perspective, emphasizing the synergy between human and artifact capabilities.
The Challenge of Explainability: Adamson, a Past President of the IEEE’s Society on the Social Implications, delves into the complexities of AI systems, highlighting the concealed nature of many AI algorithms and the need for post-hoc reasoning.
Trustworthy AI: Petkovic underscores that trustworthy AI requires both accuracy and explainability. He emphasizes the importance of explainable AI (XAI) in ensuring user trust, especially in high-stakes applications.
Bias in AI: A team of researchers, including Nagpal, Singh, Singh, Vatsa, and Ratha, evaluates the behavior of face recognition models, shedding light on potential biases related to age and ethnicity.
AI in Healthcare: Dhar, Siuly, Borra, and Sherratt discuss the challenges and opportunities of deep learning in the healthcare domain, emphasizing the ethical considerations surrounding medical data.
AI in Education: Tham and Verhulsdonck introduce the “stack” analogy for designing ubiquitous learning, emphasizing the importance of a human-centered approach in smart city contexts.
Ethics in Computer Science Education: Peterson, Ferreira, and Vardi discuss the role of ethics in computer science education, emphasizing the need for emotional engagement to understand the potential impacts of technology.
A Call to Action
As guest editors deeply engaged in human-centric approaches to AI, we challenge all stakeholders in the AI design process to consider the multidimensionality of AI. It’s crucial to move beyond the trade-offs mindset and prioritize accuracy and explainability. If a decision made by an AI system cannot be explained, especially in critical sectors like finance and healthcare, should it even be proposed?
This special issue is a testament to the importance of ethics, accuracy, explainability, and trustworthiness in AI. It underscores the need for a human-centered approach to designing AI systems that benefit society. For a deeper understanding of each paper and to explore the insights shared by the authors, check out the full special issue in IEEE Transactions on Technology and Society.
Do you need help determining which machine learning model is superior? This post presents a step-by-step guide using basic statistical techniques and a real case study! 🤖📈 #AIOrthoPraxy #MachineLearning #Statistics #DataScience
When employing Machine Learning to address problems, our choice of a model plays a crucial role. Evaluating models can be straightforward when performance disparities are substantial, for example, when comparing two large-language models (LLMS) on a masked language modeling (MLM) task with 71.01 and 28.56 perplexity, respectively. However, if differences among models are minute, making a solid analysis to discern if one model is genuinely superior to others can prove challenging.
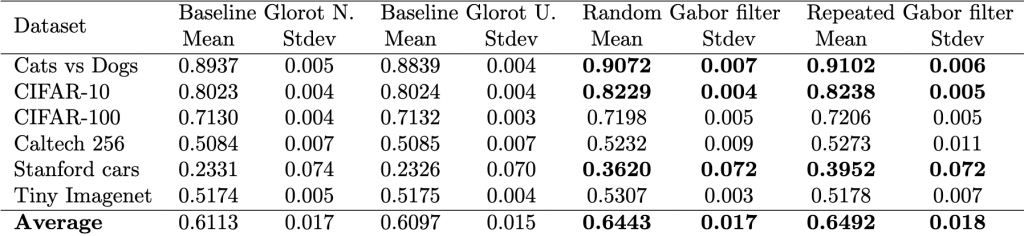
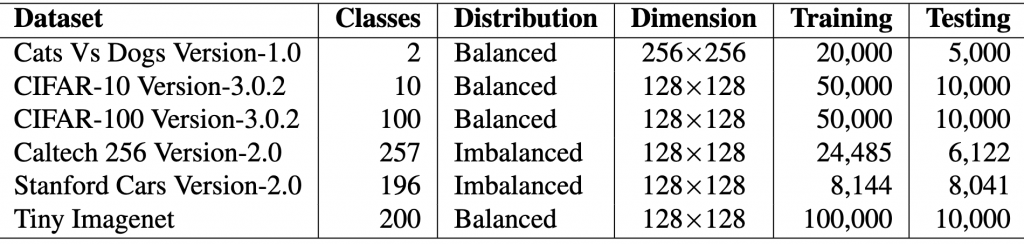
This tutorial aims to present a step-by-step guide to determine if one model is superior to another. Our approach relies on basic statistical techniques and real datasets. Our study compares four models on six datasets using one metric, standard accuracy. Alternatively, other contexts may use different numbers of models, metrics, or datasets. We will work with the tables below that show the properties of the datasets and the performance of two baseline models and two of our proposed models, for which we hope to show that they are better, which would be our hypothesis to be tested.
Summary of performance measured with standard accuracySummary of the main properties of the datasets considered in this tutorial.
One of the primary purposes of statistics is hypothesis testing. Statistical inference involves taking a sample from a population and determining how well the sample represents the population. In hypothesis testing, we formulate a null hypothesis, , and an alternative hypothesis, , based on the problem (comparing models). Both hypotheses must be concise, mutually exclusive, and exhaustive. For example, we could say that our null hypothesis is that the models perform equally, and the alternative could mean that the models perform differently.
Why is the ANOVA test not a good alternative?
The ANOVA (Analysis of Variance) test is a parametric test that compares the means of multiple groups. In our case, we have four models to compare with six datasets. The null hypothesis for ANOVA is that all the means are equal, and the alternative hypothesis is that at least one of the means is different. If the value of the ANOVA test is less than the significance level (usually 0.05), we reject the null hypothesis and conclude that at least one of the means is different, i.e., at least one model performs differently than the others. However, ANOVA may not always be the best choice for comparing the performance of different models.
One reason for this is that ANOVA assumes that the data follows a normal distribution, which may not always be the case for real-world data. Additionally, ANOVA does not take into account the difficulty of classifying certain data points. For example, in a dataset with a single numerical feature and binary labels, all models may achieve 100% accuracy on the training data. However, if the test set contains some mislabeled points, the models may perform differently. In this scenario, ANOVA would not be appropriate because it does not account for the difficulty of classifying certain data points.
Another issue with ANOVA is that it assumes that the variances of the groups being compared are equal. This assumption may not hold for datasets with different levels of noise or variability. In such cases, alternative statistical tests like the Friedman test or the Nemenyi test may be more appropriate.
Friedman test
The Friedman test is a non-parametric test that compares multiple models. In our example, we want to compare the performance of different models, i.e., two baseline models, Gabor randomized, and Gabor repeated, on datasets. First, the test calculates the average rank of each model’s performance on each dataset, with the best-performing model receiving a rank of 1. The Friedman test then tests the null hypothesis, , that all models are equally effective and their average ranks should be equal. The test statistic is calculated as follows:
(1)
where is the average ranking of each model.
The test result can be used to determine whether there is a statistically significant difference between the performance of the models by making sure that is not less than the critical value for the distribution for a particular confidence value . However, since could be too conservative, we also calculate the statistic as follows:
(2)
Based on the critical value, , and , we evaluate ;
once the null hypothesis is rejected, we apply a posthoc test. For this, we use the Nemenyi test to establish whether models differ significantly in their performance.
We will start the process of getting this test done by ranking the data. First, we can load the data and verify it with respect to the table shown earlier.
import pandas as pd
import numpy as np
data = [[0.8937, 0.8839, 0.9072, 0.9102],
[0.8023, 0.8024, 0.8229, 0.8238],
[0.7130, 0.7132, 0.7198, 0.7206],
[0.5084, 0.5085, 0.5232, 0.5273],
[0.2331, 0.2326, 0.3620, 0.3952],
[0.5174, 0.5175, 0.5307, 0.5178]]
model_names = ['Glorot N.', 'Glorot U.', 'Random G.', 'Repeated G.']
df = pd.DataFrame(data, columns=model_names)
print(df.describe()) #<- use averages to verify if matches table
Output:
Glorot N. Glorot U. Random G. Repeated G.
count 6.000000 6.000000 6.000000 6.000000
mean 0.611317 0.609683 0.644300 0.649150
std 0.240422 0.238318 0.206871 0.200173
min 0.233100 0.232600 0.362000 0.395200
25% 0.510650 0.510750 0.525075 0.520175
50% 0.615200 0.615350 0.625250 0.623950
75% 0.779975 0.780100 0.797125 0.798000
max 0.893700 0.883900 0.907200 0.910200
Next, we rank the models and get their averages like so:
data = df.rank(1, method='average', ascending=False)
print(data)
print(data.describe())
Output:
Glorot N. Glorot U. Random G. Repeated G.
0 3.0 4.0 2.0 1.0
1 4.0 3.0 2.0 1.0
2 4.0 3.0 2.0 1.0
3 4.0 3.0 2.0 1.0
4 3.0 4.0 2.0 1.0
5 4.0 3.0 1.0 2.0
Glorot N. Glorot U. Random G. Repeated G.
count 6.000000 6.000000 6.000000 6.000000
mean 3.666667 3.333333 1.833333 1.166667
std 0.516398 0.516398 0.408248 0.408248
min 3.000000 3.000000 1.000000 1.000000
25% 3.250000 3.000000 2.000000 1.000000
50% 4.000000 3.000000 2.000000 1.000000
75% 4.000000 3.750000 2.000000 1.000000
max 4.000000 4.000000 2.000000 2.000000
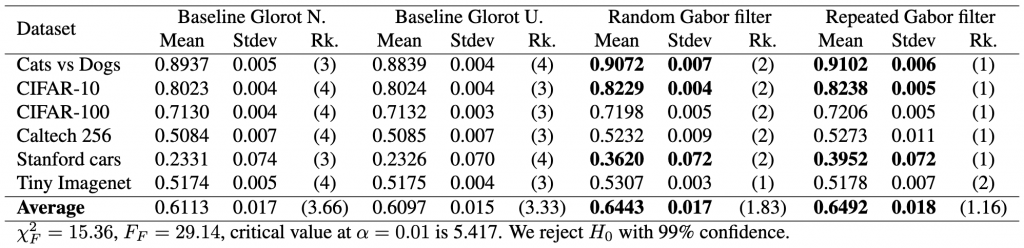
With this information, we can expand our initial results table to show the rankings by dataset and the average rankings across all datasets for each model.
Now that we have the rankings, we can proceed with the statistical analysis and do the following:
(3)
(4)
The critical value at is 5.417. Thus, because the critical value is below our statistics obtained, we reject with 99% confidence.
The critical value can be obtained from any table that has the F distribution. In the table the degrees of freedom across columns (denoted as ) is , that is the number of models minus one; the degrees of freedom across rows (denoted as ) is , that is, the number of models minus one, times the number of datasets minus one. In our case this is and .
Nemenyi Test
The Nemenyi test is a post-hoc test that compares multiple models after a significant result from Friedman’s test. The null hypothesis for Nemenyi is that there is no difference between any two models, and the alternative hypothesis is that at least one pair of models is different.
The formula for Nemenyi is as follows:
where is the critical difference of the Studentized range distribution at the chosen significance level and is the number of groups. The value can be obtained from the following table:
Critical values for the Nemenyi test, which is conducted following the Friedman test, with two-tailed results.
Thus, for our particular case study, the critical differences are:
(5)
(6)
Since the difference in rank between the randomized Gabor and baseline Glorot normal is 1.83 and is less than the , we conclude Gabor is better. Similarly, since the difference in rank between the fixed Gabor and baseline Glorot uniform is 2.17 and is less than the , we conclude that Gabor is better. Yes, there is sufficient statistical evidence to show that our model is better with high confidence.
Things we would like to see in papers
First of all, it would be nice to have a complete table that includes the results of the statistical tests as part of the caption or as a footnote, like this:
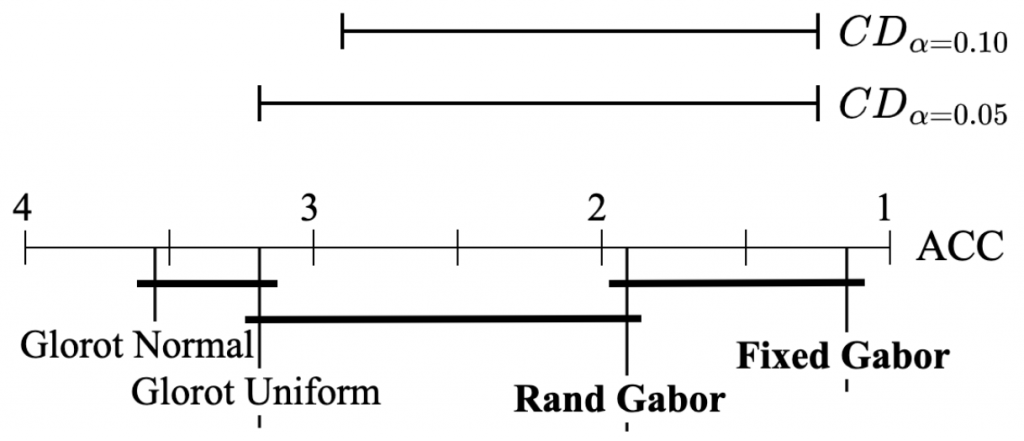
Second of all, graphics always help! A simple and visually appealing diagram is a powerful way to represent post hoc test results when comparing multiple classifiers. The figure below, which illustrates the data analysis from the table above, displays the average ranks of methods along the top line of the diagram. To facilitate interpretation, the axis is oriented so that the best ranks appear on the right side, which enables us to perceive the methods on the right as superior.
Comparison of all models against each other with the Nemenyi test. Models not significantly different at α = 0.10 or α = 0.05 are connected.
When comparing all the algorithms against each other, the groups of algorithms that are not significantly different are connected with a bold solid line. Such an approach clearly highlights the most effective models while also providing a robust analysis of the differences between models. Additionally, the critical difference is shown above the graph, further enhancing the visualization of the analysis results. Overall, this simple yet powerful diagrammatic approach provides a clear and concise representation of the performance of multiple classifiers, enabling more informed decision-making in selecting the best-performing model.
Main Sources
The statistical tests are based on this paper:
Demšar, Janez. “Statistical comparisons of classifiers over multiple data sets.” The Journal of Machine learning research 7 (2006): 1-30.
The case study is based on the following research:
Rai, Mehang. “On the Performance of Convolutional Neural Networks Initialized with Gabor Filters.” Thesis, Baylor University, 2021.
Summary: The President of the United States, Joe Biden, has recently authorized an Executive Order intending to enhance racial equity and foster support for marginalized communities via the federal government. The Order mandates that federal agencies employing artificial intelligence (AI) systems assume novel equity responsibilities and instructs them to forestall and rectify any form of discrimination, including safeguarding the public from the perils of algorithmic discrimination.
What you should know:The recent Executive Order on Further Advancing Racial Equity and Support for Underserved Communities Through The Federal Government emphasizes the importance of advancing equity for all, including communities that have long been underserved, and addressing systemic racism in the US policies and programs. This order implies that AI systems should be designed to ensure that they do not perpetuate or exacerbate inequities and should be used to address the unfair disparities faced by underserved communities. It is also implied that the Federal Government should work with civil society, the private sector, and State and local governments to redress unfair disparities and remove barriers to Government programs and services, which could be facilitated by the development and deployment of ethical and responsible AI systems. Additionally, the order emphasizes the need for evidence-based approaches to equitable policymaking and implementation, which can be achieved through collecting and analyzing data on the impacts of AI systems on different communities. Therefore, AI practitioners should ensure that their systems are designed, developed, and deployed to promote equity, fairness, and inclusivity and are aligned with the Federal Government’s commitment to advancing racial equity and supporting underserved communities.
Following President’s Executive Order, we at the CSEAI recognize the critical role of artificial intelligence in promoting fairness, accountability, and transparency. As a research center committed to developing responsible AI techniques, we believe our work can help meet the challenges and opportunities of emerging regulation, standardization, and best practices in AI systems. We are inviting industry members to partner with us financially and take part in collaborative research on trustworthy AI. Our mission is to provide applicable, actionable, standard practices in trustworthy AI and train a workforce that enables fairness, accountability, and transparency. We believe our work will help mitigate AI adoption’s operational, liability, and reputation risks.
The CSEAI brings together leading universities to conduct collaborative research in responsible AI techniques. We are committed to workforce development and providing accessible standards, best practices, testing, and compliance. We are proud to be a part of the NSF IUCRC Program and are excited to be supported by the NSF, which provides a standard agreement, organizational, and legal framework.
Join us in creating a better future for all Americans by developing responsible AI practices that promote fairness, accountability, and transparency. By partnering with the CSEAI, you will have the opportunity to work with a dedicated team of researchers, participate in cutting-edge research, and help shape the future of AI. Contact us today to learn more about partnering with the CSEAI.
Quantum computing is a rapidly emerging interdisciplinary research area that integrates concepts from mathematics, physics, and engineering. For scientific rigor and successful progress in the field, it demands contributions from various STEM areas.
In this context, we are pleased to announce the International Conference on Emergent and Quantum Technologies (ICEQT’23), to be held on July 24-27, 2023, in Las Vegas, NV. The conference aims to provide an opportunity for researchers in the field of quantum machine learning and machine learning researchers interested in applying AI to enhance quantum computing algorithms, to present and discuss recent advancements in their areas of expertise.
Notably, there has been an increasing interest from machine learning researchers to apply AI to the quantum computing domain, and vice versa. As a result, we cordially invite submissions of original research papers that present state-of-the-art contributions in the following areas:
Foundations of Quantum Computing and Quantum Machine Learning
Quantum computing models and paradigms, e.g., Grover, Shor, and others
Quantum algorithms for Linear Systems of Equations
Quantum Tensor Networks and their Applications in QML
Quantum Machine Learning Algorithms
Quantum Neural Networks
Quantum Hidden Markov Models
Quantum PCA
Quantum SVM
Quantum Autoencoders
Quantum Transfer Learning
Quantum Boltzmann machines
Theory of Quantum-enhanced Machine Learning
AI for Quantum Computing
Machine learning for improved quantum algorithm performance
Machine learning for quantum control
Machine learning for building better quantum hardware
Quantum Algorithms and Applications
Quantum computing: models and paradigms
Quantum algorithms for hyperparameter tuning (Quantum computing for AutoML)
Quantum-enhanced Reinforcement Learning
Quantum Annealing
Quantum Sampling
Applications of Quantum Machine Learning
Fairness and Ethics in Quantum Machine Learning
We look forward to receiving your submissions and to welcoming you to ICEQT’23.
All submissions that are accepted for presentation will be included in the proceedings published by IEEE CPS. To ensure consistency in formatting, authors should follow the general typesetting instructions available on the IEEE’s website, including single-line spacing and a 2-column format. Additionally, authors of accepted papers must agree to the IEEE CPS standard statement regarding copyrights and policies on electronic dissemination.
Prospective authors are encouraged to submit their papers through the conference’s evaluation website at https://american-cse.org/drafts/. More information about the conference, including submission guidelines, can be found on our website at https://baylor.ai/iceqt/.
Important Deadlines
April 12, 2023: Submission of papers: https://american-cse.org/drafts/ – Full/Regular Research Papers (maximum of 8 pages) – Short Research Papers (maximum of 5 pages) – Abstract/Poster Papers (maximum of 3 pages)
May 1, 2023: Notification of acceptance (+/- two days)
May 16, 2023: Final papers + Registration
June 21, 2023: Last day for hotel room reservation at a discounted price.
July 24-27, 2023: The 2023 World Congress in Computer Science, Computer Engineering, and Applied Computing (CSCE’23: USA) Which includes the International Conference on Emergent and Quantum Technologies (ICEQT’23)
Chairs: Dr. Pablo Rivas, Baylor University Dr. Javier Orduz, Earlham College
Large Language Models (LLMs) have become a hot topic in the world of machine learning, with chatbots like ChatGPT and other models gaining widespread popularity. However, keeping up with the latest research and advancements in this rapidly evolving field can be challenging. To help you catch up, we’ve compiled a list of 11 essential research papers that every LLM enthusiast should read. From the original Transformer architecture to recent innovations in efficiency and alignment, these papers will give you a comprehensive understanding of the field and help you stay ahead of the curve. So whether you’re a seasoned LLM practitioner or just getting started, read on to discover the key papers that will take your understanding of this exciting field to the next level.
Foundational Papers on LLM Architecture and Pretraining:
“Attention is All You Need” by Vaswani et al.: This paper introduces the Transformer architecture, which uses scaled dot-product attention to process sequences of tokens. It has since become the basis for many state-of-the-art LLMs. (https://arxiv.org/abs/1706.03762)
“BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” by Devlin et al.: This paper describes BERT, a powerful LLM that uses masked language modeling to pre-train a bidirectional Transformer encoder. BERT has achieved impressive results on various natural language processing tasks. (https://arxiv.org/abs/1810.04805)
“Improving Language Understanding by Generative Pre-Training” by Radford et al.: This paper introduces GPT, an LLM that uses a Transformer decoder to generate text based on a given prompt. It was one of the first models to demonstrate the effectiveness of large-scale unsupervised pretraining. (https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf)
“BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension” by Lewis et al.: BART is an LLM that combines elements of both encoder and decoder architectures and can be fine-tuned for a variety of natural language tasks. (https://arxiv.org/abs/1910.13461)
Methods for Improving LLM Efficiency:
“FlashAttention: A Scalable Framework for Efficient Attention Mechanisms” by Yang et al.: This paper proposes FlashAttention, a more efficient attention mechanism that reduces memory consumption and computational complexity in LLMs. (https://arxiv.org/abs/2205.14135)
“Cramming: Efficient Training of Large-Scale Models without Layerwise Pretraining” by Li et al.: This paper introduces a novel training method for LLMs that enables them to be trained on a single GPU without the need for layerwise pretraining. (https://arxiv.org/abs/2212.14034)
Methods for Controlling LLM Outputs:
“InstructGPT: Controllable Text Generation with Content-Planning Transformer” by Xiong et al.: InstructGPT is an LLM that allows for more precise control over the generated text by incorporating a content-planning module into the Transformer decoder. (https://arxiv.org/abs/2203.02155)
“Constitutional AI: Aligning Language Models with Human Values” by Amodei et al.: This paper proposes a framework for aligning LLMs with human values and provides an example of how it can be used to prevent the generation of harmful text. (https://arxiv.org/abs/2212.08073)
Alternative (ChatGPT) LLM Architectures:
“BLOOM: A Distributed Open-Source Implementation of LLMs” by Nadkarni et al.: BLOOM is an open-source implementation of LLMs that enables distributed training across multiple machines. (https://arxiv.org/abs/2211.05100)
“Sparrow: A Large-Scale Language Model for Conversational AI” by Li et al.: Sparrow is an LLM developed by DeepMind for conversational AI and features a unique architecture that enables more efficient and accurate text generation. (https://arxiv.org/abs/2209.14375)
“BlenderBot 3: Recipes for Building Large-Scale Conversational Agents” by Roller et al.: BlenderBot 3 is an LLM developed by Facebook Meta for conversational AI and includes the ability to search the internet for information to incorporate into its responses. (https://arxiv.org/abs/2208.03188)
Important Ethical Concerns Regarding LLMs:
“On the Opportunities and Risks of Foundation Models” by Rishi Bommasani et al. This paper discusses the opportunities and risks associated with “foundation models,” a new class of machine learning models trained on large and diverse datasets. The paper highlights the technical, social, and ethical challenges of deploying foundation models in various domains. (https://arxiv.org/abs/2108.07258)
“GPT-3: Its Nature, Scope, Limits, and Consequences” by Luciano Floridi & Massimo Chiriatti. This paper examines the capabilities and limitations of GPT-3, a state-of-the-art language model, and argues that it is not designed to pass tests of mathematical, semantic, or ethical questions. The paper concludes that GPT-3 is not the beginning of a general form of artificial intelligence. (https://link.springer.com/article/10.1007/s11023-020-09548-1)
“On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜” by Emily M. Bender et al. This paper raises concerns about the risks associated with LLMs like GPT-3, including their environmental and financial costs, and recommends strategies for mitigating those risks. (https://dl.acm.org/doi/abs/10.1145/3442188.3445922)
Before you go ahead and start reading these papers, remember that LLMs such as ChatGPT and its alternatives have revolutionized NLP and hold immense potential for a wide range of applications. However, we must also be mindful of the ethical concerns surrounding these models, such as potential biases and risks of misuse. As the field continues to evolve, we must prioritize ethical considerations and work towards developing models that align with human values and promote the greater good. With the right approach, large language models can enable us to build a more inclusive and equitable future where AI and human collaboration can drive innovation and positive change.
Misty and Andrew, under the direction of Dr. Pablo Rivas, will be working on designing data collection strategies for the project. Their goal is to gather relevant information to support the research and ensure the accuracy of the findings.
Meanwhile, under Dr. Tomas Cerny’s direction, Patrick, Mia, Austin, and Garrett will focus on data visualization and large graph understanding. Their role is crucial in helping to understand and interpret the data collected so far.
The research project investigates the feasibility of automating the detection of illegal goods or services within online marketplaces. As more people turn to online marketplaces for buying and selling goods and services, it is becoming increasingly important to ensure the safety of these transactions.
The project will first analyze the text of online advertisements and marketplace policies to identify indicators of suspicious activity. The findings will then be adapted to a specific context – locating stolen motor vehicle parts advertised via online marketplaces – to determine general ways to identify signals of illegal online sales.
The project brings together the expertise of computer science, criminology, and information systems to analyze online marketplace technology platform policies and identify platform features and policies that make platforms more vulnerable to criminal activity. Using this information, the researchers will generate and train deep learning-based language models to detect illicit online commerce. The models will then be applied to markets for motor vehicle parts to assess their effectiveness.
This research project represents a significant step forward in the fight against illegal activities within online marketplaces. The project results will provide law enforcement agencies and online marketplaces with valuable insights and evidence to help them crack down on illicit goods or services sold on their platforms.
We are incredibly excited to see what Misty, Andrew, Patrick, Mia, Austin, and Garret will accomplish through this project. We can’t wait to see their impact on online criminal activity research. Stay tuned for updates on their progress and more information about this cutting-edge project.
This week at the lab, we read the following paper, and here is our summary:
Huang, Hsin-Yuan, Michael Broughton, Masoud Mohseni, Ryan Babbush, Sergio Boixo, Hartmut Neven, and Jarrod R. McClean. “Power of data in quantum machine learning.” Nature communications 12, no. 1 (2021): 2631.
Summary
This work focuses on the advancement of quantum technologies and their impact on machine learning. The two paths towards the quantum enhancement of machine learning include using the power of quantum computing to improve the training process of existing classical models and using quantum models to generate correlations between variables that are inefficient to represent through classical computation. The authors show that this picture is incomplete in machine learning problems where some training data are provided, as the provided data can elevate classical models to rival quantum models. The authors present a flowchart for testing potential quantum prediction advantage based on prediction error bounds for training classical and quantum ML methods based on kernel functions. This elevation of classical models through some training samples is illustrative of the power of data. The authors also show that, “training a specific classical ML model on a collection of training examples would give rise to a prediction model with
(1)
for a constant . Hence, with training data, one can train a classical ML model to predict the function up to an additive prediction error .” They also show that a slight geometric difference between kernel functions defined by classical and quantum ML guarantees similar or better performance in prediction by classical ML. On the other hand, a sizeable geometric difference indicates the possibility of a large prediction advantage using the quantum ML model.
Additionally, the authors introduced ”projected quantum kernels” and demonstrated, through empirical results, that these outperformed all tested classical models in prediction error. This work provides a guidebook for generating ML problems that showcase the separation between quantum and classical models.
Intellectual Merit
This work provides a theoretical and computational framework for comparing classical and quantum ML models. The authors develop prediction error bounds for training classical and quantum ML methods based on kernel functions, which provide provable guarantees and are very flexible in the functions they can learn. The authors also develop a flowchart for testing potential quantum prediction advantage, a function-independent prescreening that allows one to evaluate the possibility of better performance. The authors provide a constructive example of a discrete log feature map, which gives a provable separation for their kernel. They rule out many existing models in the literature, providing a powerful sieve for focusing the development of new data encodings.
Broader Impact
The authors’ contributions to the field of quantum technologies and machine learning have significant broader impacts. The development of a flowchart for testing potential quantum prediction advantage provides a tool for researchers and practitioners to determine the possibility of better performance using quantum ML models. The authors’ framework can also be used to compare and construct hard classical models, such as hash functions, which have applications in cryptography and secure communication. The authors’ work has the potential to accelerate the development of new data encodings, leading to more efficient and accurate machine learning models. This has far-reaching implications for various applications, including image recognition, text translation, and even physics applications, where machine learning can revolutionize how we analyze and interpret data. The paper was organized and written by collaborating with three famous quantum institutes: Google Quantum AI, the Institute for Quantum Information and Matter at Caltech, and the Department of Computing and Mathematical Sciences at Caltech.
Khanal, B., Orduz, J., Rivas, P. et al. Supercomputing leverages quantum machine learning and Grover’s algorithm. J Supercomput 79, 6918–6940 (2023). https://doi.org/10.1007/s11227-022-04923-4. [ bib | .pdf ]
Quantum computing, a field that has drawn significant attention recently, promises to revolutionize how we approach computational problems. In Bikram Khanal’s paper titled “Supercomputing leverages quantum machine learning and Grover’s algorithm,” we delve deep into the intricacies of quantum computing, with a particular focus on Grover’s algorithm and its potential applications in quantum machine learning. This journal article is an extended version of an earlier conference paper found here.
Understanding Quantum Computing and Grover’s Algorithm
At the heart of our paper is a comprehensive discussion of the basics of quantum computing. We shed light on Grover’s quantum algorithm, which promises faster search capabilities compared to classical algorithms. Our team conducted an experiment simulating classical logical circulation by exploiting the power of amplitude amplification, a core principle behind Grover’s algorithm.
The Quantum Advantage
One of the primary takeaways from our research is the potential advantage quantum computing and quantum machine learning can offer over classical counterparts. By harnessing the efficiency of quantum computers, we can significantly reduce the reliance on supercomputing power for executing complex programs. This is particularly relevant for problems that pose challenges for classical computing methods.
Exploring Quantum Machine Learning
Our paper also delves into two promising approaches in quantum machine learning:
Variational Quantum Circuits: These are quantum circuits that can be tuned variably, allowing for optimization in quantum computations.
Kernel-based Quantum Machine Learning: This approach leverages the concept of kernels, which are used in classical machine learning for various tasks, and adapts them for quantum computations.
We believe the intersection of quantum algorithms and machine learning is ripe for exploration. While there’s a lot of potential, it’s also a domain that requires rigorous research to unearth solutions that can genuinely outperform classical machine learning methods. Kernel-based approaches, in particular, hold significant promise in the near future of quantum machine learning and supercomputing.
Looking Ahead
Our journey into the world of quantum computing doesn’t end here. We have charted out an exciting roadmap for our future research:
Real-world Data Testing: We aim to test our algorithm using actual data from classical circuits. This will involve parsing the circuit and feeding it into our algorithm.
Optimizing Computational Complexity: Our goal is to enhance the efficiency of our approach, especially when compared to classical methods.
Leveraging Grover’s Algorithm for Machine Learning: We believe many classification problems in machine learning can be reframed as search problems, making them ideal candidates for Grover’s algorithm.
Kernel Methods and Grover’s Algorithm: In our future work, we plan to reformulate machine learning problems using kernel methods, aiming to solve them efficiently as search problems using Grover’s algorithm.
Finally, we are at the cusp of some groundbreaking discoveries that can redefine the supercomputing landscape. We invite readers and fellow researchers to join us on this exciting journey and keep a close watch on the advancements in this domain. Read the paper here [ bib | .pdf ].
Quantum circuit for Grover algorithm with user-defined oracle on clauses |q0⟩ AND |q3⟩ , |q1⟩ XOR |q2⟩, and |q2⟩ AND |q3⟩. Note that we need seven qubits in total. For c clauses, three in this case, we require c additional qubits and one output qubit, resulting (n + c + 1) qubits quantum circuit.





 , and an alternative hypothesis,
, and an alternative hypothesis,  , based on the problem (comparing models). Both hypotheses must be concise, mutually exclusive, and exhaustive. For example, we could say that our null hypothesis is that the models perform equally, and the alternative could mean that the models perform differently.
, based on the problem (comparing models). Both hypotheses must be concise, mutually exclusive, and exhaustive. For example, we could say that our null hypothesis is that the models perform equally, and the alternative could mean that the models perform differently.
 value of the ANOVA test is less than the significance level (usually 0.05), we reject the null hypothesis and conclude that at least one of the means is different, i.e., at least one model performs differently than the others. However, ANOVA may not always be the best choice for comparing the performance of different models.
value of the ANOVA test is less than the significance level (usually 0.05), we reject the null hypothesis and conclude that at least one of the means is different, i.e., at least one model performs differently than the others. However, ANOVA may not always be the best choice for comparing the performance of different models.
 different models, i.e., two baseline models, Gabor randomized, and Gabor repeated, on
different models, i.e., two baseline models, Gabor randomized, and Gabor repeated, on  datasets. First, the test calculates the average rank of each model’s performance on each dataset, with the best-performing model receiving a rank of 1. The Friedman test then tests the null hypothesis,
datasets. First, the test calculates the average rank of each model’s performance on each dataset, with the best-performing model receiving a rank of 1. The Friedman test then tests the null hypothesis, ![\begin{equation*} \chi_{F}^{2}=\frac{12 N}{k(k+1)}\left[\sum_{j=1}^{k} R_{j}^{2}-\frac{k(k+1)^{2}}{4}\right] \end{equation*}](https://baylor.ai/wp-content/ql-cache/quicklatex.com-e2518869970055a72a2524df63957827_l3.png "Rendered by QuickLaTeX.com")
 is the average ranking of each model.
is the average ranking of each model.
 is not less than the critical value for the
is not less than the critical value for the  distribution for a particular confidence value
distribution for a particular confidence value  . However, since
. However, since  statistic as follows:
statistic as follows:

 , and
, and 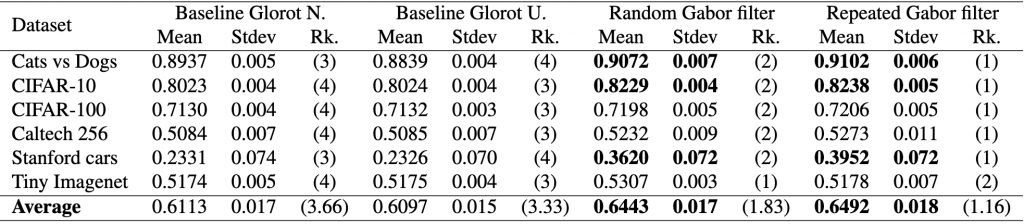
![\begin{align*} \chi_{F}^{2}&=\frac{12 \cdot 6}{4 \cdot 5}\left[\left(3.66^2+3.33^2+1.83^2+1.16^2\right)-\frac{4 \cdot 5^2}{4}\right] \nonumber \\ &=15.364 \nonumber \end{align*}](https://baylor.ai/wp-content/ql-cache/quicklatex.com-b7fd261f286621cdf8d57b028898841d_l3.png "Rendered by QuickLaTeX.com")

 is 5.417. Thus, because the critical value is below our statistics obtained, we reject
is 5.417. Thus, because the critical value is below our statistics obtained, we reject  ) is
) is  , that is the number of models minus one; the degrees of freedom across rows (denoted as
, that is the number of models minus one; the degrees of freedom across rows (denoted as  ) is
) is  , that is, the number of models minus one, times the number of datasets minus one. In our case this is
, that is, the number of models minus one, times the number of datasets minus one. In our case this is  and
and  .
.![\[CD = q_{\alpha} \sqrt{\frac{k(k+1)}{6N}}\]](https://baylor.ai/wp-content/ql-cache/quicklatex.com-31ddfa7633974f9a4c569740f85c93b8_l3.png "Rendered by QuickLaTeX.com")
 is the critical difference of the Studentized range distribution at the chosen significance level and
is the critical difference of the Studentized range distribution at the chosen significance level and  is the number of groups. The
is the number of groups. The 


 , we conclude Gabor is better. Similarly, since the difference in rank between the fixed Gabor and baseline Glorot uniform is 2.17 and is less than the
, we conclude Gabor is better. Similarly, since the difference in rank between the fixed Gabor and baseline Glorot uniform is 2.17 and is less than the  , we conclude that Gabor is better. Yes, there is sufficient statistical evidence to show that our model is better with high confidence.
, we conclude that Gabor is better. Yes, there is sufficient statistical evidence to show that our model is better with high confidence.





 training examples
training examples  would give rise to a prediction model
would give rise to a prediction model  with
with

 . Hence, with
. Hence, with  training data, one can train a classical ML model to predict the function
training data, one can train a classical ML model to predict the function  up to an additive prediction error
up to an additive prediction error  .” They also show that a slight geometric difference between kernel functions defined by classical and quantum ML guarantees similar or better performance in prediction by classical ML. On the other hand, a sizeable geometric difference indicates the possibility of a large prediction advantage using the quantum ML model.
.” They also show that a slight geometric difference between kernel functions defined by classical and quantum ML guarantees similar or better performance in prediction by classical ML. On the other hand, a sizeable geometric difference indicates the possibility of a large prediction advantage using the quantum ML model.